![[Java] 아스키코드 & 유니코드](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbisMDY%2FbtrlUOxwYjD%2FIpbHS7RujJ4XhEivmmMdCK%2Fimg.jpg)
초창기에는 다양한 방법으로 문자를 표현했는데, 호환 등 여러 문제가 발생했다. 이런 문제를 해결하기 위해 ANSI에서 ASCII(American Standard Code for Information Interchange)라는 표준 코드 체계를 제시했고, 현재 이 코드가 일반적으로 사용되고 있다.
ASCII는 각 문자를 7비트로 표현하므로 총 128(= 27)개의 문자를 표현할 수 있다.
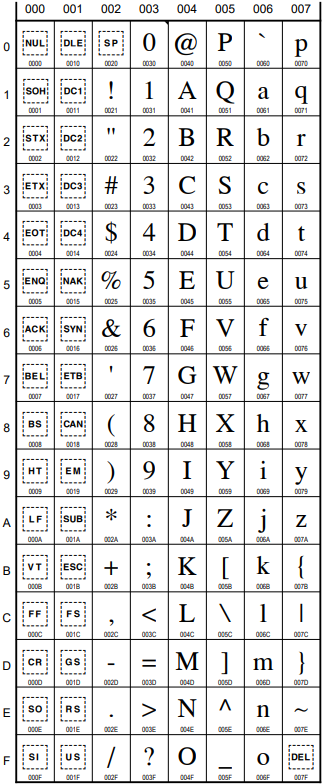
| 0000000 | NUL | 0100000 | Space | 1000000 | @ | 1100000 | ` |
| 0000001 | SOH (Start of Heading) | 0100001 | ! | 1000001 | A | 1100001 | a |
| 0000010 | STX (Start of Text) | 0100010 | “ | 1000010 | B | 1100010 | b |
| 0000011 | ETX (End of Text) | 0100011 | # | 1000011 | C | 1100011 | c |
| 0000100 | EOT (End of Transmission) | 0100100 | $ | 1000100 | D | 1100100 | d |
| 0000101 | ENQ (Enquiry) | 0100101 | % | 1000101 | E | 1100101 | e |
| 0000110 | ACK (Acknowledge) | 0100110 | & | 1000110 | F | 1100110 | f |
| 0000111 | BEL (Bell) | 0100111 | ‘ | 1000111 | G | 1100111 | g |
| 0001000 | BS (Backspace) | 0101000 | ( | 1001000 | H | 1101000 | h |
| 0001001 | HT (Horizontal Tabulation) | 0101001 | ) | 1001001 | I | 1101001 | i |
| 0001010 | LF (Line Feed) | 0101010 | * | 1001010 | J | 1101010 | j |
| 0001011 | VT (Vertical Tabulation) | 0101011 | + | 1001011 | K | 1101011 | k |
| 0001100 | FF (Form Feed) | 0101100 | , | 1001100 | L | 1101100 | l |
| 0001101 | CR (Carriage Return) | 0101101 | - | 1001101 | M | 1101101 | m |
| 0001110 | SO (Shift Out) | 0101110 | . | 1001110 | N | 1101110 | n |
| 0001111 | SI (Shift In) | 0101111 | / | 1001111 | O | 1101111 | o |
| 0010000 | DLE (Data Link Escape) | 0110000 | 0 | 1010000 | P | 1110000 | p |
| 0010001 | DC1 (Device Control 1) | 0110001 | 1 | 1010001 | Q | 1110001 | q |
| 0010010 | DC2 (Device Control 2) | 0110010 | 2 | 1010010 | R | 1110010 | r |
| 0010011 | DC3 (Device Control 3) | 0110011 | 3 | 1010011 | S | 1110011 | s |
| 0010100 | DC4 (Device Control 4) | 0110100 | 4 | 1010100 | T | 1110100 | t |
| 0010101 | NAK (Negative Acknowledge) | 0110101 | 5 | 1010101 | U | 1110101 | u |
| 0010110 | SYN (Synchronous Idle) | 0110110 | 6 | 1010110 | V | 1110110 | v |
| 0010111 | ETB (End of Transmission Block) | 0110111 | 7 | 1010111 | W | 1110111 | w |
| 0011000 | CAN (Cancel) | 0111000 | 8 | 1011000 | X | 1111000 | x |
| 0011001 | EM (End of Medium) | 0111001 | 9 | 1011001 | Y | 1111001 | y |
| 0011010 | SUB (Substitute) | 0111010 | : | 1011010 | Z | 1111010 | z |
| 0011011 | ESC (Escape) | 0111011 | ; | 1011011 | [ | 1111011 | { |
| 0011100 | FS (File Separator) | 0111100 | < | 1011100 | \ | 1111100 | | |
| 0011101 | GS (Group Separator) | 0111101 | = | 1011101 | ] | 1111101 | } |
| 0011110 | RS (Record Separator) | 0111110 | > | 1011110 | ^ | 1111110 | ~ |
| 0011111 | US (Unit Separator) | 0111111 | ? | 1011111 | _ | 1111111 | DEL |
각 나라별 언어를 모두 표현하기 위해 나온 코드 체계가 유니코드(unicode)다. 유니코드는 사용중인 운영체제, 프로그램, 언어에 관계없이 문자마다 고유한 코드 값을 제공하는 새로운 개념의 코드다. 언어와 상관없이 모든 문자를 16비트로 표현하므로 최대 65,536자를 표현할 수 있다.
유니코드 표준은 애플(Apple), HP, IBM, 썬(Sun), MS, 오라클(Oracle)과 같은 업계에서 채택되었으며, XML, 자바, ECMAScript, LDAP, CORBA 등의 표준에서 사용되고 있다.
3. 아스키코드 & 유니코드 예문
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import java.util.Scanner;
public class Test
{ public static void main(String[] args)
{ // 알파벳을 아스키 코드로
Scanner sc = new Scanner(System.in);
System.out.println("알파벳을 입력해주세요");
char alpa = sc.nextLine().charAt(0);
int ialpa = (int)alpa;
System.out.println(ialpa);
// 아스키 코드를 알파벳으로
System.out.println("숫자를 입력해주세요");
int alpaNum = sc.nextInt();
char calpa = (char)alpaNum;
System.out.println(calpa);
}
}
|
cs |
- char alpa = sc.nextLine().charAt(0);
반환형 > char / charAt(0)이기 때문에 0번째의 값을 alpa가 char형으로 값을 가지게 된다.
- int ialpa = (int)alpa;
그 값이 ialpa라는 값으로 int의 자료형으로 가게 된다.
- int ialpa = (int)alpa;
반환형 > int / 입력받은 유니코드 숫자를 ialpa에 저장
- char calpa = (char)alpaNum;
그 값을 char 형으로 calpa에 저장
'Java > Day9' 카테고리의 다른 글
| [Java] Math.random() (0) | 2021.11.17 |
|---|---|
| [Java] 메소드 오버로딩 & 메소드 시그니처 (0) | 2021.11.12 |